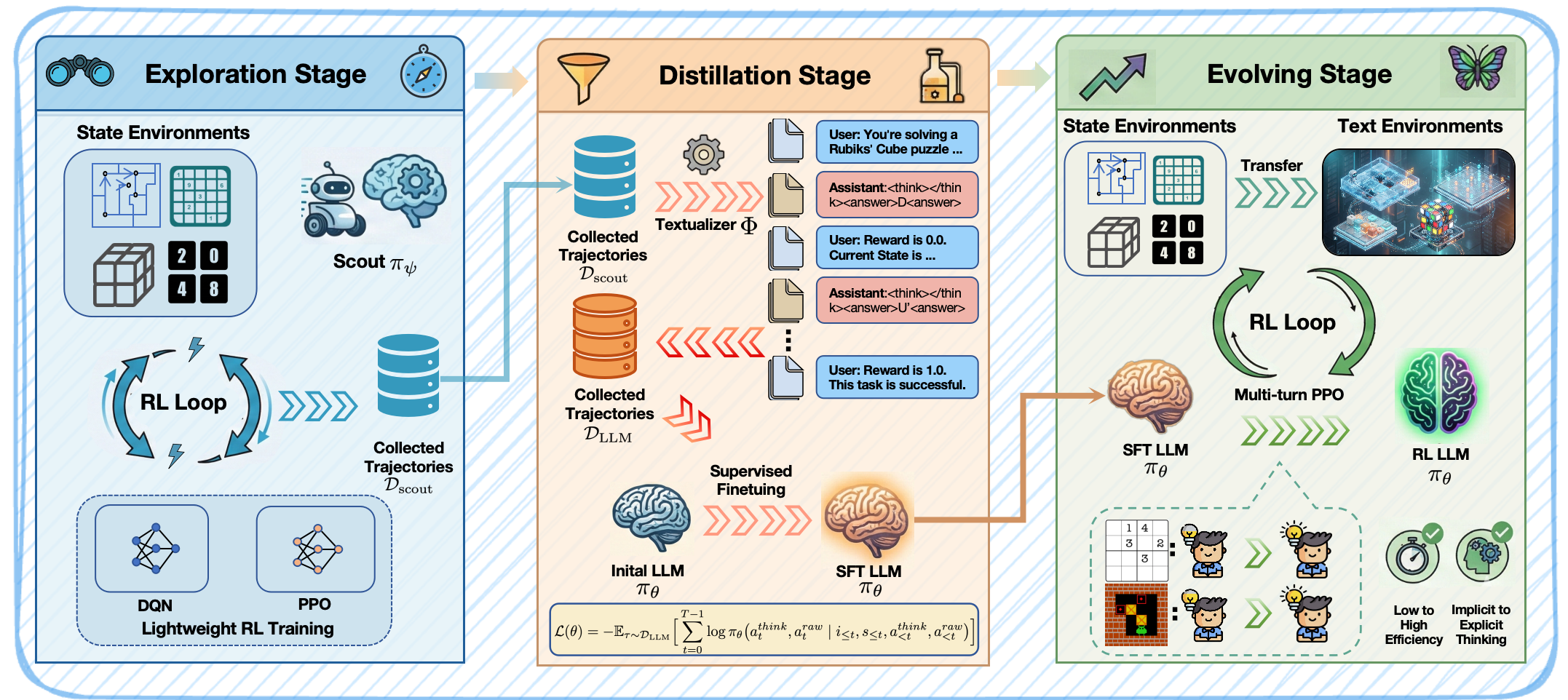
While Large Language Models (LLMs) excel in language-based agentic tasks, their applicability to unseen, nonlinguistic environments (e.g., symbolic or spatial tasks) remains limited. Previous work attributes this performance gap to the mismatch between the pretraining distribution and testing distribution. In this work, we demonstrate the primary bottleneck is the prohibitive cost of exploration: mastering these tasks requires extensive trial-and-error, which is computationally unsustainable for parameter-heavy LLMs operating in a high dimensional semantic space. To address this, we propose SCOUT (Sub-Scale Collaboration On Unseen Task), a novel framework that decouples exploration from exploitation. We employ lightweight "scouts" (e.g., small MLPs) to probe environmental dynamics at a speed and scale far exceeding LLMs. The collected trajectories are utilized to bootstrap the LLM via Supervised Fine-Tuning (SFT), followed by multi-turn Reinforcement Learning (RL) to activate its latent world knowledge. Empirically, SCOUT enables a Qwen2.5-3B-Instruct model to achieve an average score of 0.86, significantly outperforming proprietary models, including Gemini-2.5-Pro (0.60), while saving about 60% GPU hours consumption.
Applying LLMs directly to unseen physical or symbolic environments reveals a critical inefficiency. As noted in The Bitter Lesson (Sutton, 2019), leveraging computation for search and learning is key. However, for LLMs:
Endless complexity: It is hard to fully simplify and cover all tasks during pretraining as the real world is unbounded, involving "endless complexity".
Mismatch of Spaces: LLMs explore a vast language space, whereas many unseen tasks require discrete, low-dimensional actions. Forcing an LLM to perform "trial-and-error" from scratch is computationally wasteful.
The Bitter Lesson: Depending solely on language priors limits scalability. Leveraging computation (searching and learning) is far more effective than relying on predefined knowledge in a long run.
Sub-Scale Collaboration: Delegate the "dirty work" of initial exploration to lightweight Scouts. They are cheap, fast, and can run on CPUs. The LLM only enters when it can learn from high-quality "Experience" rather than the heavy trial-and-error.
By shifting the exploration phase to scouts (which are ~100,000x smaller than LLMs), SCOUT drastically reduces the computational footprint required to train competent agents.
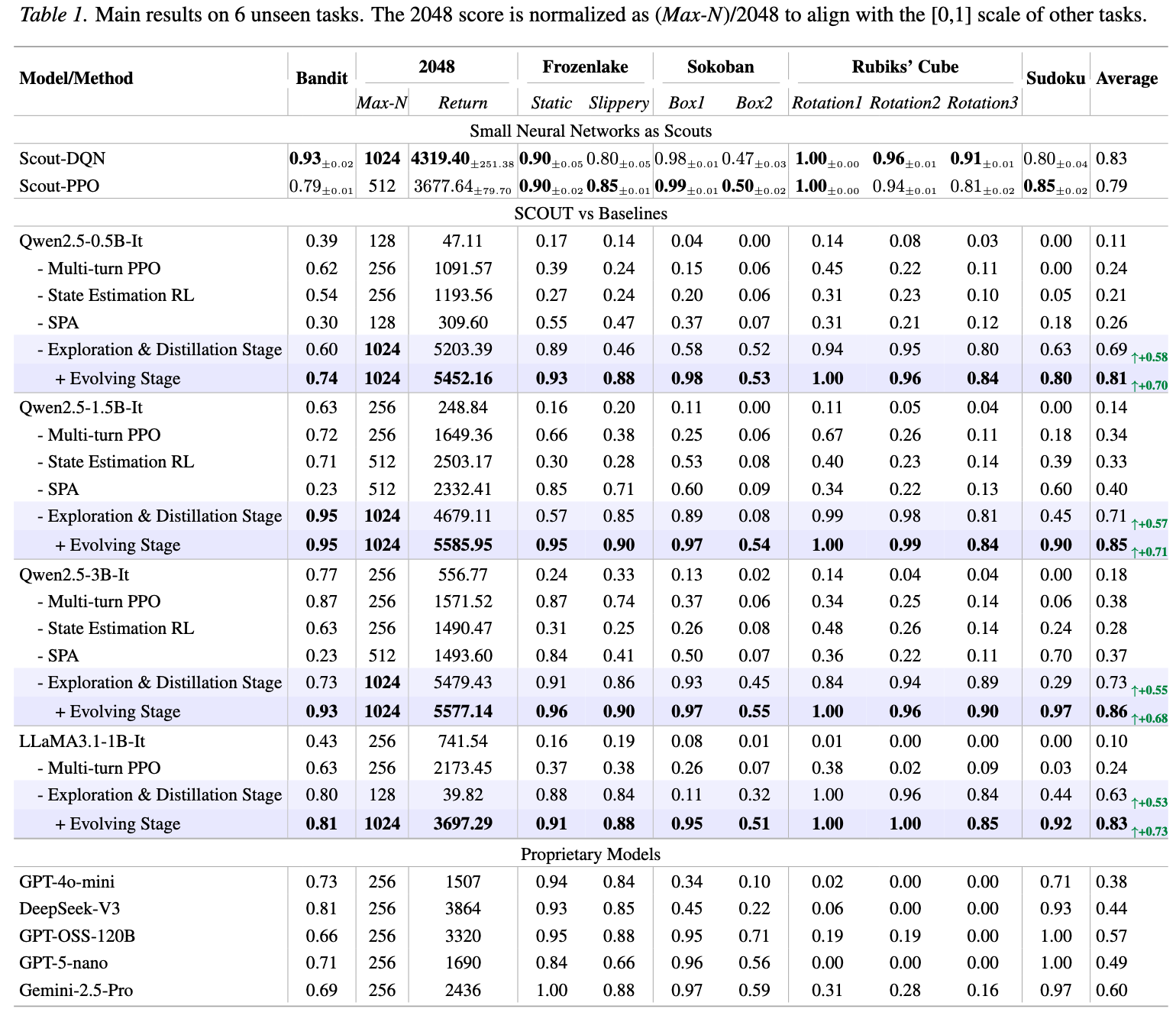
Table 1: Main results on 6 unseen tasks. The 2048 score is normalized (Max-N)/2048 to align with the [0,1] scale of other tasks.
A fascinating finding in our work is the transition of knowledge representation. During the Distillation Stage, the LLM mimics the scout's actions, but the "thoughts" are left blank. During the Evolving Stage (Multi-turn RL), the LLM spontaneously fills these thought blocks with explicit reasoning strategies to maximize reward.
The SFT model after the Distillation Stage leaves its thought blank. However, after RL, the model explicitly identifies missing numbers in rows and columns in its thought.
Figure 3: The LLM "activates" latent world knowledge to explain the Scout's intuition using language.
@article{wang2026language,
title={Language-based Trial and Error Falls Behind in the Era of Experience},
author={Wang, Haoyu and Ma, Guozheng and Cui, Shugang and Kong, Yilun and Luo, Haotian and Shen, Li and Gao, Mengya and Wu, Yichao and Wang, Xiaogang and Tao, Dacheng},
journal={arXiv preprint arXiv:2601.21754},
year={2026}
}